How To Use ‘grep’: The Complete Linux Command Guide
Grep is a pretty useful command line on Linux systems, but it can be challenging to grasp its potential and exhaustive list of options. I have summarized the main things you should know about grep in this article.
The ‘grep’ command on Linux is used to search for specific text within files (or standard input). Files are scanned line by line, and the grep options are used as a filter to display only the matching lines.
Check the table of contents below to easily find what you’re looking for, or continue reading to get a full overview of this command.
Command syntax
The grep command syntax is structured like this:grep <options> <patterns> <file>
So, we start with the main command name, and then we have three parts:
- Options that apply either to the filter (case sensitivity, for example) or to the output itself (show line numbers).
- Patterns are basically the filters we apply to the file that tell the command what we are looking for.
- The file parameter can be just a file name, a group of files or the standard input directly (the result of another command, for example).
Usage examples
Let’s take a few examples to turn this syntax template into actionable command lines.
Finding text in a file
The most basic use of the “grep” command is to search for a specific string in a file, to only display matching lines.
In this case, the command syntax will be:grep <search_string> <filename>
So, for example:grep raspberrytips /var/log/apache2/access.log

As you can see in my screenshot, it only displays the line containing the word “raspberrytips” in my Apache access.log file.
Download your exclusive free PDF containing the most useful Linux commands to elevate your skills!
Download now
The output will be slightly different depending on your system or terminal. In my example, the pattern is colored in red in the results, so I can quickly identify where it is, but more about that later.
Filter the results of another command
Grep is also often used after a pipe to filter the results of a previous command. It’s not necessarily the smartest way to use it, as most commands have options built-in for that, but it’s often how I use it anyway.
Did you know?
In simple terms, the pipe symbol on Linux takes the result of the first command and passes it to another command.
For example: ls | headWill only list the first 10 files in the current directory.

Join Our Community!
Connect, learn, and grow with other Raspberry Pi enthusiasts. Support RaspberryTips and enjoy an ad-free reading experience. Get exclusive monthly video tutorials and many other benefits.
Learn moreHere are some typical examples:find /home/pat -size +1M | grep <string>
ls -l | grep <string>
The first command searches for any file larger than 1MB in my home folder, but only displays the one matching a specific name (can be a file extension, a subfolder name or whatever is included in the find result).
The second command lists files in the current directory, but only displays the one containing a certain string. Be aware that the filter applies to everything on the result line, not only the file name, here is a typical example:

Not only does the filter apply to the file names, but also to the other columns (permissions and dates). So make sure you’re aware of this when you use grep with a pipe, it’s not perfect.
There are often better ways to do the same (find has options to filter file names) or you may need to adjust the first command parameters (don’t use -later with this if you use grep on file names after that). But it’s still an efficient way to get the result you want in record time, even if it’s not perfect.
Search in multiple files
Another one I often use is to search for a specific word in many files, or in a folder.
Instead of giving only one filename in the <file> parameter, you can use the wildcard ‘*’ to search in multiple files at once, for example:grep Error *
This will search in all files in the current folder, and display matching lines, starting with the file name:

I’ll give you better options to go even further, but by adding the wildcard (*) in your file parameter, you can search multiple files at once.
Download your exclusive free PDF containing the most useful Linux commands to elevate your skills!
Download now
Main options
In the previous examples, we didn’t use any option, but the “grep” command has a lot of options to customize the filter or the output.
Here are the main parameters that can be used after the grep command to get exactly the result you’re looking for:
- -i: Ignores case distinctions in both the pattern and the input files.
- -v: Inverts the match, showing lines that don’t match the given pattern.
- -c: Counts the number of lines that match the pattern.
- -l: Lists only the names of files with matching lines, once for each file.
- -n: Shows the line number before each line that matches the pattern.
- -m NUM: Stops reading a file after NUM matching lines.
- -o: Shows only the part of a line matching the pattern.
- -r: Recursively searches for the pattern in all files under each directory.
- -e PATTERNS: Allows for multiple search patterns.
- -f FILE: Takes patterns from a file, one per line.
- -q: Quiet mode; doesn’t output anything, just returns an exit status.
- -A NUM: Shows NUM lines of trailing context after matching lines.
- -B NUM: Shows NUM lines of leading context before matching lines.
- -C NUM: Shows NUM lines of output context around the matching lines.
- -w: Matches only whole words.
- -H: Print the file name for each match.
You can combine options by sticking them together, as with most Linux commands, for example:grep -nH <filter> <file>
This will prefix each result with the file name and line number.
You can get the full list of options with man:man grepBut these are the main ones you need to know.
Tips
Here are a few bonus tips to get the most out of this command.
Highlight matches
Most SSH clients and GUI terminals will do it by default, but if needed, you can add this parameter to get the search word highlighted in your results:grep --color <pattern> <file>
This will give you similar results as on all my previous screenshots. The pattern will generally be colored in red in the results.
Combining commands
This isn’t necessarily the best practice or the smartest way to do this, but it’s possible to use several grep commands in a row:grep Error syslog | grep apache
This will give you only the lines containing “Error” in the log file, and then filter them again to only the ones containing “apache”.
We have seen this earlier, but you can easily add the grep command after another command, to filter the results. Typically, after the find command, something like:find / -size +1G | grep mp4
It will list all files larger than 1GB on your drive but only display the MP4 files (or files with “mp4” in their names to be more accurate).
Search only in specific file types
We have seen earlier that you can use the wildcard symbol (*) to search in multiple files at once:grep -nHr Error *
But it doesn’t mean you can filter the file names and types. In a similar way, this will only search in log files:grep -nH Error *.log
And this is only in the access log (from Apache):grep -nH Error /var/log/apache2/access.*
Alternatives
These variants of grep are depreciated, but still provided for backward compatibility:
- egrep: same as grep -E (extended regular expressions).
- fgrep: same as grep -F (fixed strings).
- rgrep: same as grep -r (recursive).
The first time you’re seeing them? Forget about them. I’m only mentioning them in case you have previous experience with them. It’s safer to use the “grep” command alternative instead.
Download your exclusive free PDF containing the most useful Linux commands to elevate your skills!
Download now
Related questions
What does grep stand for?
The name grep stands for “Global Regular Expression Print”. This term comes from the ed command g/re/p, where g is for global, re is for regular expression, and p is for print.
In short, grep is used to search for text patterns defined by regular expressions and print the lines where these patterns are found.
How does grep work with regular expressions?
While grep is generally used with simple filters (typically a string you’re looking for in a file or files), it can also be used with regular expressions for more advanced searches.
The syntax remains the same, the only difference is that you can include a regular expression in the pattern:grep <options> <pattern> <file>
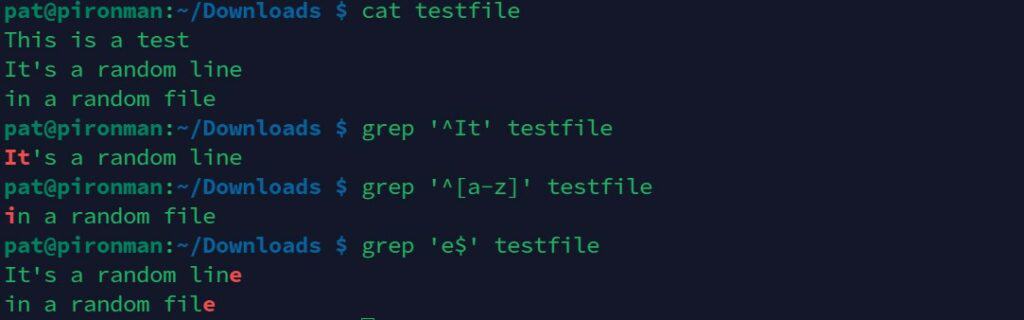
So, for example:grep '^Error' filenameTo only show lines containing the word “Error” at the beginning of the line.
Download your exclusive free PDF containing the most useful Linux commands to elevate your skills!
Download now
If you are looking for exclusive tutorials, I post a new course each month, available for premium members only. Join the community to get access to all of them right now!
Going further
- Official manual (gnu.org).

Master Linux Commands
Want to level up your Linux skills? Here is the perfect solution to become efficient on Linux.